The usual balanced block mixer is a two-input-port two-output-port mechanism which guarantees that any change on one input port will produce a change on both output ports. This property is sufficient to guarantee the overall diffusion needed in wide block ciphers.
Balanced Block Mixers are essentially two orthogonal Latin square combiners, and have both computational and table look-up realizations. (They were originally called Block Mixing Transforms.) There is even a hybrid realization which will greatly reduce table storage, at the cost of some added computation in each access.
A Balanced Block Mixer is an m-input-port m-output-port mechanism with the following properties:
A Balanced Block Mixer can be seen as two cryptographic combiners which are "orthogonal" (thus allowing their output to be transformed back to the original values). Each of these combiners provides "mixing" between whole blocks, with a good statistical balance between the inputs. Any particular value on an output port can be produced by any possible value on an input port, given some value on the other input port.
The properties of each part of a Balanced Block Mixer appear to be a generalization of additive combining like exclusive-OR. The overall structure of a Balanced Block Mixer is that of an orthogonal pair of Latin squares, which may be implemented either by computation when and as needed, or as explicit look-up tables.
If we have two input ports labeled A and B, two output ports labeled X and Y, and some irreducible mod 2 polynomial p of degree appropriate to the port size, a Balanced Block Mixer is formed by the equations:
X = 3A + 2B (mod 2)(mod p), Y = 2A + 3B (mod 2)(mod p).This particular Balanced Block Mixer is a self-inverse, and so can be used without change whether enciphering or deciphering. One possible value for p is 100011011 in binary (this is an irreducible mod 2 polynomial).
An unusual advantage of the computational realization is scalability. We can make a proper Balanced Block Mixer of any reasonable size which requires only linear computational effort with port size. Not only can we use very large Balanced Block Mixers, we can also use arrays of smaller Balanced Block Mixers for about the same overall cost. This turns out to be very useful, as this sort of mixing can be repeated with blocks of decreasing size to provide guaranteed mixing to increasingly fine block elements.
ASSERTION: (We have a finite field.) Mod-2 polynomials modulo some irreducible polynomial p generate a finite field.
(Comment: Proofs can use algebra.)
PROPOSITION: (Example Balanced Block Mixer.) The equations
X = 3A + 2B = A + 2(A + B) Y = 2A + 3B = B + 2(A + B)and the inverse
A = X + 2(X + Y) B = Y + 2(X + Y)mod 2 and mod p, where p is some irreducible mod 2 polynomial, represent a Balanced Block Mixer.
A = A + 2(A + B) + 2(A + 2(A + B) + B + 2(A + B))
A = A + 2(A + B) + 2(A + B) = A
and
B = B + 2(A + B) + 2(A + 2(A + B) + B + 2(A + B))
B = B + 2(A + B) + 2(A + B) = B
so the inverse does exist for any polynomials A and B. And a
function with an inverse on the same range must be one-to-one.
Suppose some change C is added to A:
X = 3A + 2B (mod 2, mod p)
X' = 3(A+C) + 2B
X' = 3A + 3C + 2B
dX = X' - X = 3C
So, for any non-zero change C, we have a different X.
Similar reasoning covers the other term, and the other
equation.)
X = 3A + 2B = 3A + 2B'
so
X + 3A = 2B = 2B'
which implies that
B = B'
which is a contradiction. Fixing B or working on the other
block reason similarly.
A consequence of this particularly efficient construction is that this Balanced Block Mixer has essentially no "strength" of its own. As one example of mixing without strength, consider DES with a known key: this is also a "weak" operation, but would nevertheless provide good, invertible mixing for two 32-bit input blocks.
If we have two input ports labeled A and B, two output ports labeled X and Y, and orthogonal Latin square arrays Q and R of order appropriate to the port size, a Balanced Block Mixer is formed by the equations:
X = Q[A][B], Y = R[A][B].where Q[A][B] signifies indexing the stored array Q by row and column.
When we know Q and R, we can construct inverse arrays Q' and R' which take X and Y back to A and B.
One advantage of the table look-up realization is that the squares can be very random-like, nonlinear, strong and keyed. And even though the table realization is not scalable, these relatively small mixings can be extended to cover large blocks with Fast Fourier Transform (FFT)-style mixing patterns. The simple storage-oriented structure of this realization seems ideal for modern chip implementations.
DEFINITION: (Square Array.) A square array of order n is a two dimensional array of n*n storage elements indexed by row and column. Each possible combination of row and column values will select a storage position which can hold a single symbol or value.
DEFINITION: (Latin Square Array.) A Latin square array of order n contains each of n unique symbols or values n times, such that each possible value occurs exactly once in each row and column.
DEFINITION: (Array Pair.) Two square arrays of order n can form an ordered pair of values when each square is indexed with the same row and column values.
DEFINITION: (Orthogonal Array Pair.) An array pair is said to be orthogonal when all n*n possible row and column index values produce every possible ordered pair exactly once.
COROLLARY: (Invertibility.) An orthogonal array pair is always invertible, since no ordered pair value occurs more than once.
PROPOSITION: (Example Balanced Block Mixer.) Two orthogonal Latin squares Q and R of appropriate order with array indexing:
X = Q[A][B], Y = R[A][B].form a Balanced Block Mixer. Q[A][B] signifies indexing the stored array Q by row and column,
Suppose some change C is added to A:
X = Q[A][B]
X' = Q[A+C][B]
For any non-zero change C, the new index A+C selects a different
entry within column B. Since each entry in one column of a
Latin square is unique, X' is necessarily different than X.
Similar reasoning covers the column index B, and the other combiner R.
Stepping the other index (B) reasons similarly.
One consequence of the table realization is the ability to explicitly specify strong, nonlinear Latin squares. The need to store the table is a cost, but table access can be substantially faster than computation.
It is probably easiest simply to consider a Balanced Block Mixer to be a pair of orthogonal Latin squares, realized either by computation or explicit values in a look-up table.
Any really new component seems strange when first proposed, because there is no background showing such a component is useful. For example, transistors were difficult to understand and use when they were new, and at that time the need for an amplification component was already well established. While Balanced Block Mixers are not the next transistor, they do have certain advantages which are worth taking seriously.
Computational-based realizations of Balanced Block Mixers like that of Example 1 are typically weak. A question that immediately arises is whether there can be any advantage to using a weak component in a cipher. But, by itself, exclusive-OR is also weak (having no strength at all), and is used in ciphers all the time without similar questions.
Table-based realizations of Balanced Block Mixers like those in Example 2 are necessarily limited to small block widths. The obvious question here is whether there can be any advantage to using a small mixing component. But even a small mixing component can be used in FFT-like patterns, and this does support the mixing of large blocks.
The advantage of the Balanced Block Mixer lies in the properties which the component is guaranteed to possess. In particular, any change at all to one input port value is guaranteed to change both output port values. The use of this simple property is sufficient to guarantee overall diffusion or "avalanche" in a block cipher.
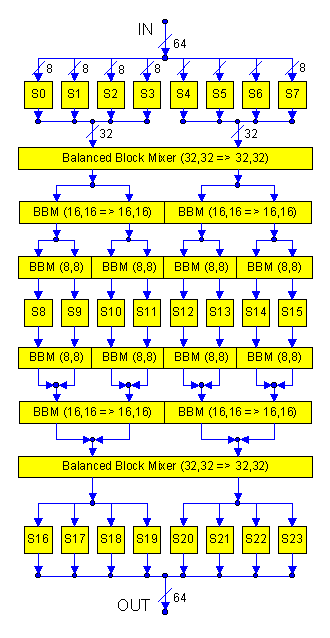
One example of the practical use of Balanced Block Mixers is a 64-bit block cipher based on 8-bit substitution tables:
S S S S S S S S
------mix------
--mix-- --mix--
mix mix mix mix
S S S S S S S S
mix mix mix mix
--mix-- --mix--
------mix------
S S S S S S S S
The 64-bit input is split and enters eight 8-bit substitution tables. Then we have a single mixing on the two 32-bit-wide values accumulated from four tables each. Then we have two mixings on the four 16-bit-wide values across the block, and four mixings on the eight 8-bit-wide values across the block. This result is again substituted through eight substitution tables, and then mixed again in three layers in opposite order, before being substituted a last time in eight 8-bit substitution tables. In practice, each table would be initialized by individual shuffling according to a cryptographic key.
Scalable mixing is fundamental to this design, for this is how we can achieve diffusion across the whole 64-bit block while using tiny 8-bit-wide confusion components. If even one bit of the input block changes, both 32-bit output from the first mixing will change, as will all four 16-bit results and then all eight 8-bit results from mixing. Accordingly, Balanced Block Mixing has provably conducted the change to all of the internal 8-bit tables. Because these tables are all shuffled or "keyed," each responds with a "random" value. These values are then mixed again, and we can guarantee that the result is a function of the "random" value produced by each internal table.
This 64-bit block cipher contains exactly two component types, each of which is susceptible to deep mathematical analysis. The substitution tables are each simply arbitrary selections among all possible permutations. The overall structure is a simple logical architecture, and far simpler than any 16-round cipher. This leads to a cipher about which we can actually begin to make serious mathematical statements. We can know more about this type of cipher than we can about most others.
Another way to mix data across a wide block relies on the fast, perfectly-balanced mixing in Balanced Block Mixers. Another example is a 32-bit block "cipher." (Note that it is certainly possible to explore and record the full transformation of 32-bit cipher, no matter what the keyspace of the cipher is. Thus, a 32-bit block cipher must be considered "weak.")
In the 32-bit block "cipher" example, two pairs of the four substitution table outputs are mixed into two element pairs. One element of each of these pairs is then mixed with an element of the other pair. This different sort of mixing architecture also produces a result in which each element is a function of every input element.
S S S S
mix mix
*mix*
*mix*
S S S S
*mix*
*mix*
mix mix
S S S S
Here we have only byte-sized mixing, and "*mix*" means to mix the two bytes in the columns covered by "mix" or which have "*" symbols.
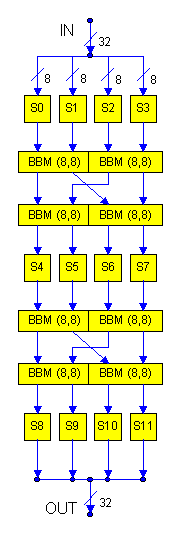
This design uses the beginning of FFT-style mixing patterns. While it is set up to use keyed substitutions to strengthen and hide weak linear mixing, it could instead use strong, keyed, table look-up mixing. This means that we might be able to eliminate the need for keyed substitutions entirely:
mix mix
*mix*
*mix*
(Again, we have only byte-sized mixing, and "*mix*" means to mix
the two bytes in the columns covered by "mix" or which have "*"
symbols.) This leaves us with one overall mixing from 4 bytes to
4 bytes composed of 2 mixing sub-layers of 2 mixings each.
An extension of the same mixing concept produces a 64-bit block cipher (and could be extended to an arbitrary power-of-2 number of substitution- or cipher-width elements).
S S S S S S S S
mix mix mix mix
*mix* *mix*
*mix* *mix*
*--mix--*
*--mix--*
*--mix--*
*--mix--*
S S S S S S S S
*--mix--*
*--mix--*
*--mix--*
*--mix--*
*mix* *mix*
*mix* *mix*
mix mix mix mix
S S S S S S S S
(Again, we have only byte-sized mixing, and "*mix*" means to mix the two bytes in the columns covered by "mix" or which have "*" symbols.) Like the previous example, two mixing layers produce sets of four elements, each of which is a function of four input elements. Then, just one more mixing step mixes the two sets of elements (in any of 24 possible permutations per mixing layer) to two sets of results, each element of which is a function of all eight original input elements. (The mixing pattern is somewhat different so it can be shown easily; many mixing patterns are available, and equally powerful.)

Note that many different "FFT-style" mixing interconnections can mix all of the input values into each of the output values. Selecting a particular mixing architecture could provide some amount of keying, which might even be dynamic.
Alternately, one might seek to identify a mixing architecture which has an especially fast implementation. In particular, it is possible to have a fixed interconnection permutation which, when used repeatedly, will perform full mixing. This could be useful in a hardware table realization which uses one row of Balanced Block Mixers repeatedly, and would have only log n rounds of one table look-up delay each.
mix mix mix mix
*mix* *mix*
*mix* *mix*
*--mix--*
*--mix--*
*--mix--*
*--mix--*
(As before, and "*mix*" means to mix the two bytes in the columns covered by "mix" or which have "*" symbols.) But if we do use keyed table realizations, we probably can avoid using the substitutions, and probably also avoid doing the mixing twice. Here we have 3 mixing sub-layers of 4 mixings each which performs a thorough, keyed, nonlinear and independent mixing. Each of the 4 mixings in each sub-layer could occur simultaneously in separate hardware. Strength issues probably depend upon the number of keyed mixers used and possible dynamic changes in the mixing pattern. A single keyed orthogonal pair of Latin squares of order 256 at least potentially has a keyspace of 3368 bits.
It is possible to combine some of the advantages of both computational and table realizations.
Consider the design of a 256-byte mixing large-block cipher (the 2048-bit block may allow us to avoid "operating modes" like CBC, and would have room for options like authentication and dynamic keying). Now, we could use just a single BBM and step across byte-pairs until we have done them all; this would involve 128 look-up and computation delays for each of 8 mixing sub-layers.
Alternately, we could also use 128 separate byte BBM's in hardware, and do 128 mixings in parallel, in one look-up and computation delay. With 128 hybrid byte BBM's we need only 64KB of store. This is 1/2 the store used in one table look-up realization.
We will need 8 mixing sub-layers, which we can either implement with more hardware, or by latching a permuted result from each previous mixing. (We should probably stay away from using the term "rounds" for such operation, because of its association with Feistel structures.)
In this way we perform a complete nonlinear mixing of 256 bytes into 256 bytes in 8 look-up and computation delays. This may be faster than we could get the data to and from the ciphering engine.
Last updated: 1997-01-09