Dynamic Substitution is a replacement for the weak exclusive-OR combiner normally used in stream ciphers. Dynamic Substitution is generally nonlinear, with substantial internal state. Multiple nonlinear combining levels are practical, as are selections among multiple different combiners. The resulting strength can support the use of weaker but faster keying generators. Additional strength is available in "hardened" and customized versions.
Dynamic Substitution is a reversible nonlinear combiner based on substitution.
A combiner is a cryptographic mechanism which mixes a confusion or keying sequence with data. A combiner is the heart of a stream cipher, which generally uses an "additive" combiner such as exclusive-OR.
Unfortunately, additive combiners have absolutely no strength at all: If an Opponent somehow comes up with some plaintext and matching ciphertext, an additive combiner immediately reveals the confusion sequence. This allows the Opponent to begin work on breaking the confusion sequence generator.
In a similar known-plaintext situation, Dynamic Substitution hides the confusion sequence (to some extent). This strengthens the cipher and allows the use of a weaker (and faster) confusion sequence generator.
The sources of the Dynamic Substitution idea were:
The Dynamic Substitution mechanism consists of one or more invertible substitution tables, and some way to change the arrangement of the values in the tables.
An invertible substitution table contains each possible value exactly once. For example, a "byte-wide" table will have 256 byte-value entries. Any entry in the table can be selected by a value in the range 0..255, and every possible substitution value 0..255 will occur exactly once.
Each substitution table is "keyed" or shuffled under the control of a keyed random number generator (RNG). The keying process is very conventional. However, in Dynamic Substitution, a form of shuffling continues during operation, and this is unique.
One way to "harden" simple substitution is to re-shuffle the entire table after every character substituted. But what does this gain us? The only entry in the table which can possibly be revealed by a substitution operation is the particular entry which was just used. Accordingly, if we change the table after each substitution, the only entry in the table that we really need to change is the just-used entry.
What do we change the just-used entry to? Well, we want the new entry to be "unknown," that is, an even-probability selection from among all possible values. One way to do this is to use a random numerical value to select some entry in the table. Then we swap the just-used and selected entries (which are occasionally the same).
In operation, a data character is substituted into ciphertext or a result character. Then the substitution table is permuted. In the usual case, the content of the just-used entry is swapped with the content of some entry selected by a keyed random number stream.
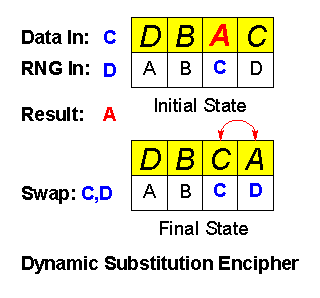
Suppose we have a simple four-element substitution table, initialized as: (D,B,A,C) for addresses A..D. That is, address A contains D, address B contains B, and so on. In this way, the table transforms any input value in the range A..D into some output value in the same range. This is classical Simple Substitution.
INITIAL STATE Forward Table
--- --- --- ---
Table Value | D | B | A | C |
--- --- --- ---
Table Location A B C D
Data In (DI): C
Random In (RI): D
Data Out (DO) = Fwd[DI] = Fwd[C] = A
Swap( Fwd[DI], Fwd[RI] ) = Swap( Fwd[C], Fwd[D] )
FINAL STATE Forward Table
--- --- --- ---
Table Value | D | B | C | A |
--- --- --- ---
Table Location A B C D
Suppose we have a Data input of C and RNG input of D: The data value uses location C, which contains the value A; this is the result or "ciphertext." The RNG value selects location D, and then the values in the "used" and "selected" locations are exchanged. This produces the changed table: (D,B,C,A). (This is perhaps the most efficient of many possible forms of Dynamic Substitution.)
In the table, each substitution element changes "at random" whenever it is used, and the more often it is used, the more often it changes. The effect of this is to adaptively "even out" symbol-frequency statistics which are the principle weakness of simple substitution. Also, the elements are changed "behind the scenes" (the exchange is not visible until future data selects one of the exchanged elements), and this tends to hide the confusion sequence.
Suppose we have the same substitution table we had before: (D,B,A,C). For deciphering we also need the inverse table: (C,B,D,A) which we originally compute from the forward table. We assume that we will have the transmitted ciphertext and also exactly the same RNG value as at the far end. The RNG is initialized from the same key and so produces exactly the same sequence on both ends.
INITIAL STATE Inverse Table Forward Table
--- --- --- --- --- --- --- ---
Table Value | C | B | D | A | | D | B | A | C |
--- --- --- --- --- --- --- ---
Table Location A B C D A B C D
Data In (DI): A
Random In (RI): D
Data Out (DO) = Inv[DI] = Inv[A] = C
Swap( Inv[DI], Inv[Fwd[RI]] ) = Swap( Inv[A], Inv[C] )
Swap( Fwd[Inv[DI]], Fwd[RI] ) = Swap( Fwd[C], Fwd[D] )
FINAL STATE Inverse Table Forward Table
--- --- --- --- --- --- --- ---
Table Value | D | B | C | A | | D | B | C | A |
--- --- --- --- --- --- --- ---
Table Location A B C D A B C D
Suppose we have a Ciphertext value of A and RNG input of D: The ciphertext uses location A in the inverse table, which contains the value C, which is the result or "plaintext": our original value. The RNG selects location D in the forward table, which contains value C. Then we exchange the values in locations A,C (the enciphered data and enciphered RNG values) in the inverse table. Then we exchange the values in locations C,D (the plaintext data and plaintext RNG values) in the forward table, just as occurs during enciphering. This serves to keep both the forward and inverse tables "in sync" with the enciphering system.
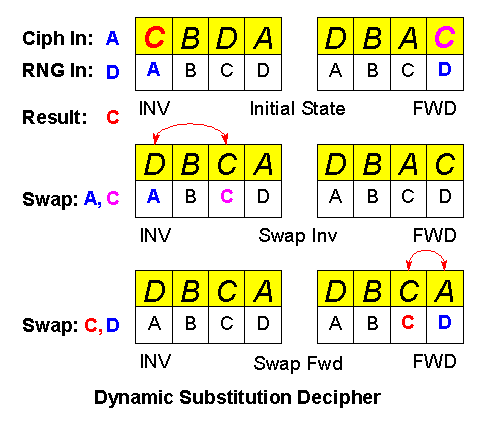
The point of this is to minimize the amount of work we have to do to maintain the inverse table (which does the deciphering). The locations to be swapped in the inverse table are the enciphered plaintext and the enciphered RNG value. Now, the enciphered plaintext is just the ciphertext value, which we have, but the enciphered RNG value is something we do not have. Therefore, we also maintain a forward table to encipher the RNG value so we can update the inverse table. This means that the forward table also must be maintained or "kept in sync." The forward table is updated by swapping elements selected by the plaintext and RNG values, which we now have, just as occurs during enciphering.
If we consider a substitution table and changes controller as a single component, we find that one such component can be used to encipher, and two such components can be used to decipher:
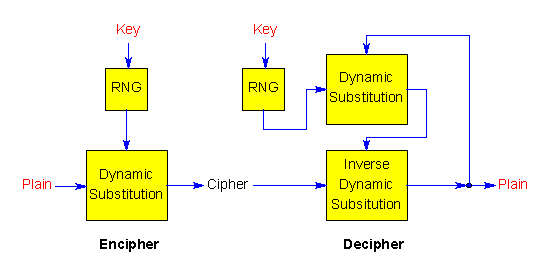
The difference between the normal and inverse components is just the arrangement of the substitution table.
Dynamic Substitution can be used to replace exclusive-OR combining in stream ciphers. But when we find a component with new properties we also gain new design opportunities:
Whenever we have a different design, we can expect that some characteristics will be disadvantageous, at least in particular situations:
Dynamic Substitution also requires that tables be shuffled or keyed prior to use; exclusive-OR does not. Usually, though, such "initialization overhead" is a small part of the overall computation.
Dynamic Substitution is indisputably stronger than the exclusive-OR combiner used in most stream ciphers: With exclusive-OR, each byte of known-plaintext and associated ciphertext will reveal a byte from the confusion sequence. In a similar situation, Dynamic Substitution does not directly expose confusion sequence bytes.
But Dynamic Substitution is a tool, and is not by itself a guarantee of unbreakable strength. There are at least two methods for finding confusion sequence values from the basic unhardened design: known-plaintext and defined-plaintext.
One way to deduce confusion values (in a simple system with one non-hardened combiner) is to examine the ciphertext for "close" repeats of the same value. When a ciphertext value repeats, it means that a plaintext value has found where the earlier ciphertext value was moved. This plaintext value is naively the same as the earlier confusion value.
When we use Dynamic Substitution, we expect to find particular ciphertext values separated by about the same number of steps as there are different values. But over this same period there will be about twice as many values moved in the internal table as there are values in that table. This means that repeats of the expected distance often will have moved twice, and so will not identify the first confusion value. For this reason, we can use only "close" repeats, and unless the repeats are adjacent, even some of those values will not be the desired confusion value. We might instead use only "adjacent" repeats, but these are much less frequent.
So instead of known confusion values, we normally get probable confusion values, and we find those at random positions in the sequence. Or, if The Opponent has enough known-plaintext and the ability to use widely-spaced values in a solution, perhaps adjacent repeats would be used. Whether or not this is a real weakness depends on various things, including the size and strength of the confusion sequence generator or random number generator (RNG):
As usual in cryptography, we cannot expect a simple mechanism to be secure on its own. Instead, each mechanism must be used in suitably secure ways. For Dynamic Substitution, secure techniques include sequential ciphering and dynamic combiner selection, and both of these are really only useful for nonlinear combiners with internal state.
Another way to deduce confusion (again, in a simple system with one non-hardened combiner) values is to explore the table arrangement both before and after any particular substitution occurs. That is, The Opponent tries one plaintext value, then resets the system and tries another, until all possible values have been covered. (This of course implies that The Opponent can reset the system, cipher any desired message, and capture the ciphertext result. The ability to reset the system is generally not available in real designs.)
If The Opponent conducts a full table exploration just before any particular substitution, and then again after that operation, typically two table elements will have changed places. This will identify the element selected by the data value and the element selected by the confusion value. But the data value is known (since The Opponent generated the message), so the confusion value can be deduced from the original state of the table.
On the other hand, "table exploration" generally implies a defined plaintext attack, which can be prevented in other parts of the cipher. For example, when a cipher uses a random message key, the actual data-ciphering key is a random value not under the control of the user. In general, this means that every ciphering will have a different table initialization, and this means that it will be impossible for The Opponent as a user to reset the system to a known state, even though repeatedly using the same User Key. This makes it impossible for The Opponent to conduct even one table exploration.
Similarly, by selecting from among an array of separate Dynamic Substitution combiners, The Opponent would seemingly need to isolate the ciphering from each individual table. And even a small array makes it hard to associate each result with a particular table, even if a defined-plaintext attack is otherwise enabled.
Various constructions can be used to strengthen the basic Dynamic Substitution operation, up to and including re-shuffling the entire table after every character. But the combining operation can be very significantly strengthened with far less overhead than this. Two interesting approaches may be called Doubly Indirect Data and Double Random, and these may be used either separately or together.
Encipher data through the table twice, and exchange the second selected element with the random selected element.
Enciphering:
INITIAL STATE Forward Table
--- --- --- ---
Table Value | B | D | A | C |
--- --- --- ---
Table Location A B C D
Data In (DI): C
Random In (RI): D
Data Out (DO) = Fwd[Fwd[DI]] = Fwd[Fwd[C]] = B
Swap( Fwd[Fwd[DI]], Fwd[RI] ) = Swap( Fwd[A], Fwd[D] )
FINAL STATE Forward Table
--- --- --- ---
Table Value | C | D | A | B |
--- --- --- ---
Table Location A B C D
Deciphering:
INITIAL STATE Inverse Table Forward Table
--- --- --- --- --- --- --- ---
Table Value | C | A | D | B | | B | D | A | C |
--- --- --- --- --- --- --- ---
Table Location A B C D A B C D
Data In (DI): B
Random In (RI): D
Data Out (DO) = Inv[Inv[DI]] = Inv[Inv[B]] = C
temp = Inv[DI] = Inv[B] = A
Swap( Inv[DI], Inv[Fwd[RI]] ) = Swap( Inv[B], Inv[C] )
Swap( Fwd[temp], Fwd[RI] ) = Swap( Fwd[A], Fwd[D] )
FINAL STATE Inverse Table Forward Table
--- --- --- --- --- --- --- ---
Table Value | C | D | A | B | | C | D | A | B |
--- --- --- --- --- --- --- ---
Table Location A B C D A B C D
The advantage here is the added protection of decoupling the input data from the output entry. This generally prevents The Opponent from finding a previous random value when a data in value produces a match to a preceding data out.
The cost of this added strength is quite modest, being just one more indirect access when enciphering, and perhaps a new temp variable when deciphering.
Encipher data through the table once. To form an ultimate random value, encipher one random input value and additively combine it with a second random input. Then exchange the selected element with the random selected element.
Enciphering:
INITIAL STATE Forward Table
--- --- --- ---
Table Value | D | B | A | C |
--- --- --- ---
Table Location A B C D
Data In (DI): C
Random In A (RIA): D
Random In B (RIB): C
Data Out (DO) = Fwd[DI] = Fwd[C] = A
temp = RIB + Fwd[RIA] = C + Fwd[D] = C + C = A
Swap( Fwd[DI], Fwd[temp] ) = Swap( Fwd[C], Fwd[A] )
FINAL STATE Forward Table
--- --- --- ---
Table Value | A | B | D | C |
--- --- --- ---
Table Location A B C D
Deciphering:
INITIAL STATE Inverse Table Forward Table
--- --- --- --- --- --- --- ---
Table Value | C | B | D | A | | D | B | A | C |
--- --- --- --- --- --- --- ---
Table Location A B C D A B C D
Data In (DI): A
Random In A (RIA): D
Random In B (RIB): C
Data Out (DO) = Inv[DI] = Inv[A] = C
temp1 = RIB + Fwd[RIA] = C + Fwd[D] = C + C = A
temp2 = Inv[DI] = Inv[A] = C
Swap( Inv[DI], Inv[Fwd[temp1]] ) = Swap( Inv[A], Inv[D] )
Swap( Fwd[temp2], Fwd[temp1] ) = Swap( Fwd[C], Fwd[A] )
FINAL STATE Inverse Table Forward Table
--- --- --- --- --- --- --- ---
Table Value | A | B | D | C | | A | B | D | C |
--- --- --- --- --- --- --- ---
Table Location A B C D A B C D
The advantage of this method is that we absolutely know that a single byte of ciphertext cannot possibly resolve two bytes of random input.
The cost, of course, is the need for twice as many random values (which may be available anyway, when using a wide Additive RNG), plus another indirect access and exclusive-OR, when enciphering. Two new temp variables may be needed for deciphering, but if that storage is available, the cost may be just the extra indirect access and exclusive-OR.
As these two hardening methods show, a wide variety of simple manipulations can be used to strengthen the fundamental combining operation. These methods can be used in addition to the ability to use a wide range of more extensive permutations far beyond just one or two swap operations. And all of these Dynamic Substitution flavors can be used in a sequence of combinings or a selection among multiple combinings.
An effective cryptographic system should be seen as a system designed to protect the inevitable weaknesses in each of the components. For example, the fact that exclusive-OR is trivially weak does not prevent it from being used to good advantage as a balanced mixer in many ciphering designs. But a stronger component needs less protection.
Perhaps the biggest advantages of Dynamic Substitution follow from a construction based on substantial internal state. It is the Dynamic Substitution internal state which supports the use of (nonlinear) combinings in sequence. In contrast, multiple combining rarely improves strength when using (linear) exclusive-OR. It is the Dynamic Substitution internal state which also makes each combiner different, and thus supports the use of a selection from among several combiners. And, of course, there are no "different" exclusive-OR combiners. The cost is a need to store and initialize this state information.
By making use of the Dynamic Substitution internal state, a cipher can remain secure even if weakness is later found in the confusion generator subsystem. Indeed, a simpler and faster RNG can be used from the start. These are significant advantages.
Thanks to John Savard (seward@netcom.ca) for pointing out that "close" repeats in normal Dynamic Substitution ciphertext can expose confusion values.
Thanks to Keith Lockstone (klockstone@cix.compulink.co.uk) for suggesting ways to "harden" Dynamic Substitution and prevent confusion exposure.
Last updated: 1997-01-16