Many modern ciphers are based on keyed invertible substitution tables. Each such table contains exactly the same values as any other, but in a different order. In this environment, keying consists of constructing a particular arrangement of the data in each table. Ideally, every possible arrangement or permutation would be equally likely.
Separating the keying system from the actual ciphering allows the ciphering core to be as simple and fast as possible. This separation also allows each system to be analyzed largely independently.
The goal of the keying system is to construct arbitrary invertible tables under the control of a key. In a sense, the arrangement of values in each table is the "real" key for the cipher. The keying system simply processes the external key into the larger internal form required by the design.
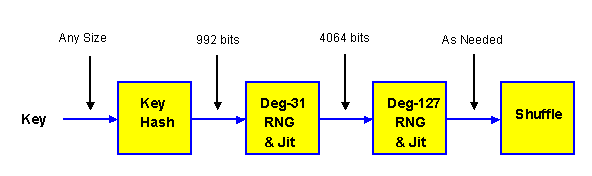
This key processing can be accomplished by using the external key to set the initial state for a random number generator (RNG), then using the RNG to shuffle the tables. Here we also use an intermediate RNG which expands the data and provides nonlinearity in the original state of the keying RNG, which helps protect against attack.
It is first necessary to convert an external key of arbitrary content and length into the fixed amount of data suitable for initializing a serious RNG. The general name for this process is hashing. By including hashing as part of the cipher, we can directly handle text keys, binary keys, voice keys, picture keys, file keys, or keys based on any information whatsoever, and of arbitrary size. And if we want a weaker cipher, we can just agree to use short external keys.
The hash result is used as the state or "seed" for the first RNG. The pseudo-random sequence from the first RNG is filtered to make it nonlinear and stronger, and the resulting sequence is used to construct the state for the second RNG. The second RNG produces a pseudo-random sequence which is also nonlinearly filtered. The resulting sequence is used to shuffle the tables.
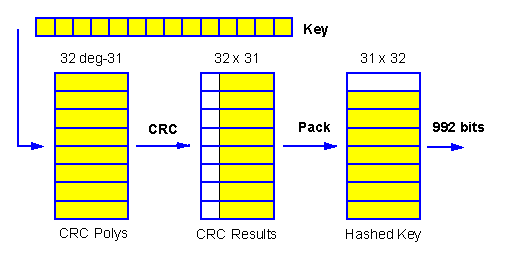
We wish to use a first RNG having 31 elements of 32 bits each, so it is convenient to develop a hash result of 992 bits from the variable-size key. For a hash of this size, we use conventional cyclic redundancy check (CRC) technology with a set of 32 different degree-31 mod-2 primitive polynomials.
Unlike ad hoc cryptographic hash functions, CRC is well understood and has a strong mathematical basis. (For an introduction, see Ramabadran and Gaitonde [5]; CRC is also mentioned in Sect 5.3 of Ritter [6].) Although CRC is a linear function, and thus contributes no added strength, it is here used only for key processing, so no added strength is needed or wanted.
Each CRC scan across the key uses a particular degree-31 polynomial, and produces a 31-bit result in a 32-bit element. So by performing 32 different CRC's using each of 32 different polynomials, we accumulate 32 results, each of which has a most-significant-bit (msb) of zero. We then delete the msb's and pack the 32 elements of 31 valid bits into 31 elements of 32 bits each. This also causes the 32 CRC results to each start at a different bit-position in the packed array.
In our current design, each CRC hashing polynomial has an approximate balance in ones and zeros. These polynomials had to be constructed, because polynomials meeting the balance requirement were not available in the literature. The general ideas behind finding irreducible and primitive mod-2 polynomials are discussed in Ritter [6], Sect 6.5. A CRC only needs irreducibles, but at degree 31 these are all primitive anyway.
CRC hashing gives us a way to handle keys of arbitrary content
and size, in a fixed, and relatively easily analyzed RNG system.
The key can be a text string or a random binary value of
arbitrary length. Keys of any reasonable size are thus directly
supported in a fixed-size hash machine.
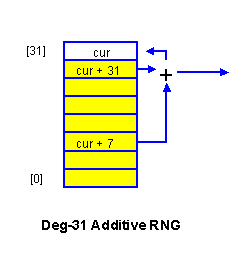
We wish to use some form of RNG to key the ciphering tables. Our published survey of ciphering RNG's [6] (Ritter, in particular Sect 4.10), revealed the Additive RNG as a very attractive choice. An Additive RNG has a large internal state, a huge proven cycle length, and especially fast operation. It is easily customized by using an appropriate primitive mod-2 feedback polynomial. And -- unlike many cryptographic RNG designs -- an Additive RNG supports almost arbitrary initialization.
The Additive RNG is described in Knuth II [2: 26-31]. Also see Marsaglia [3] for comments, and Marsaglia and Tsay [4] for a sequence length proof.
We wish to use a deg-31 Additive RNG with 32-bit elements,
which thus requires a 992-bit initialization value. We obtain
this by hashing the external key into a 31-element array of 32-bit
values. (We also scan this array looking for '1'-bits in the
least-significant-bit (lsb) of each element; if none are found,
the lsb of element [0] is made a '1'.) For best acceptance, the
mod-2 primitive trinomial is taken from Zierler and Brillhart
[7: 542].
The Additive RNG is a linear system; the sequence of values it
produces is inherently linearly related. This is a potential
weakness, which we avoid in several ways. One way is to use a
nonlinear filter which we call a "Jitterizer." (The concept of
a Jitterizer was introduced in
Sect 5.5 of
Ritter
[6].)

The approach taken here is to "drop" or delete a pseudo-random number of elements from the sequence, then "take" or pass-along another pseudo-random number of elements. Each of the elements in a "take" group is also exclusive-ORed with one of the dropped values.
When called in the "drop" phase, the Jitterizer calls the RNG extra times until the first element of the next "take" phase is reached. This value is offset and returned. When called in the "take" phase, the Jitterizer just calls the RNG once, offsets the value and returns it.
Our current Jitterizer design is constructed to drop 2..5 elements (avg. 3.5), then take 1..16 elements (avg. 8.5). This will drop out almost 30 percent of a long sequence. Each last dropped value becomes a new offset, so the 32-bit offsets change about every 8 or 9 returned values. Each first dropped value is offset, XORed down to a byte, and used to set take and drop counts.
The term "jitterizer" is used as a counterpart to the
"synchronizer" mechanisms commonly used in digital design. An
oscilloscope display which is not synchronized is said to "jitter."
The purpose of a jitterizer is to create a non-synchronized stream.
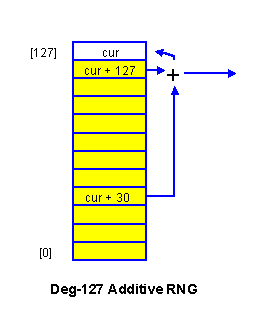
We wish to use a deg-127 Additive RNG to control the actual shuffling. Such an RNG has an internal state of 4064 bits, which we originally develop by running the deg-31 RNG until we get 127 Jitterized 32-bit elements. We also scan the resulting state to assure that at least one '1' occurs in the lsb position, and increment element [0] otherwise.
The mod-2 primitive trinomial is again taken from Zierler and
Brillhart
[7: 542]. The sequence from the second RNG is
also jitterized and used to control the shuffling.
First we initialize the tables in a counting pattern. Then we shuffle the tables. Twice.
The shuffle routine is the standard Durstenfeld [1] shuffle described in Knuth II [ 2: 139 �3.4.2.P ] and mentioned in Sect 6.7 of Ritter [6].
Suppose we have "byte wide" substitution table, an array of 256 byte elements, from index [0] through [255]: To make a random arrangement, we first select one of the entries by creating a random value on the range 0..255. We then take the value in that element and place it into some known position; it is convenient to place the value at the far end of the array. This leaves us with a empty place in the array, and an extra value which came from the far end. We might shift the second part of the table down to fill the hole and make room for the displaced value, but it is easier to simply put the displaced value in the empty position. This amounts to exchanging the values in the randomly selected position and the end of the array.
With one value positioned, we have 255 values remaining, in positions [0] through [254]. So we use a random value in the range 0..254 to select a position, and exchange the selected value with the value in position [254]. Sometimes these are the same, which is fine. We similarly fill positions [253], [252], etc., down to position [1], which also defines the remaining value in position [0].
Perhaps the hardest part of this process is the development of unbiased random values with the correct range at each step. The Additive RNG's will generate random binary 32-bit values. It is certainly possible to convert the random values to reals on the range 0..1 and then multiply by the current position. Or we could do some sort of scaled integer multiply.
Another approach is to simply get a random value, and if the result is in our desired range we accept it, otherwise we reject it and try again. Now, obviously, the likelihood of getting a value in 0..253 from a 32-bit random value is pretty low, so we first convert the 32-bit value into an 8-bit value by exclusive-ORing high and low halves, twice. Similarly, the likelihood of getting a value in 0..5 from an 8-bit random value is also pretty low, so we arrange to mask the random value in power-of-2 steps. To look for a value in 0..5, we mask the 8-bit random to 3 bits, giving a range of 0..7, so in this case we expect to find a value in our range 6 times out of 8. This approach has the advantage of clearly giving an even probability in each desired range, something which is often not as clear when using reals and scaled multiplies. The approach also skips RNG values occasionally (about 1 time in 4, on average), which adds further uncertainty to the sequence position of each RNG value used.
Since RNG is mainly used to key the tables (it does also develop the few initial values needed by the core), an attack on the RNG can be made only after an Opponent has somehow developed some amount of table content. Note that a single "byte-wide" substitution table (an array of 256 byte values) represents 1648 bits of information.
The external keys are assumed to be unknown, since, if we do not make this assumption, The Opponent can simply enter the correct key and decipher the data directly. These are secret keys and we assume that they have been distributed by some secure process.
We do not particularly care if the mechanism protects the value of the external key, since the state of the ciphering core alone is sufficient to decipher data. An Opponent who can somehow develop the core state has no need for the original key.
We do seek to defend against any ability to use some amount of known state to develop knowledge of additional state. We seek to defend against using the recovered state of one table to develop the content of other tables. We thus assume some amount of known state, and seek to prevent that knowledge from being extended to other entries or tables.
There are basically four levels of resistance in the keying system:
These arguments form the basis for an assumption of sufficient strength in the keying system.
1. Durstenfeld, R. 1964. Algorithm 235, Random Permutation, Procedure SHUFFLE. Communications of the ACM. 7: 420.
2. Knuth, D. 1981. The Art of Computer Programming, Vol. 2, Seminumerical Algorithms. 2nd ed. Addison-Wesley: Reading, Massachusetts.
3. Marsaglia, G. 1984. A current view of random number generators. Proceedings of the Sixteenth Symposium on the Interface Between Computer Science and Statistics. 3-10.
4. Marsaglia, G. and L. Tsay. 1985. Matrices and the Structure of Random Number Sequences. Linear Algebra and its Applications. 67: 147-156.
5. Ramabadran, T. and S. Gaitonde. 1988. A Tutorial on CRC Computations. IEEE Micro. August: 62-75.
6. Ritter, T. 1991. The Efficient Generation of Cryptographic Confusion Sequences. Cryptologia. 15(2): 81-139.
7. Zierler, N. and J. Brillhart. 1968. On Primitive Trinomials (Mod 2). Information and Control. 13: 541-554.
Last updated: 1997-08-22