A Variable Size Block Cipher (VSBC) is distinguished by its ability to cipher blocks of dynamically arbitrary size, to the byte, and yet produce good data diffusion across the whole block.
In dramatic contrast to conventional designs, here most diffusion occurs in simple linear BBM operations which are not intended to provide strength! By itself, linear mixing has no strength at all, but it does set the stage for keyed substitution tables which do have strength. The BBM's provide a guaranteed, exactly balanced and reversible mixing which, in a successful design, prevents individual tables from being distinguished and solved.
Here we present the ciphering core, the architecture of tables and mixing which performs actual ciphering. The tables are initialized or "keyed" by a separate process which shuffles each table independently, twice.
The first known publication of the concept of a Variable Size Block Cipher (VSBC) -- and the first published VSBC design -- was the 1995 Aug 20 sci.crypt announcement by Ritter and the resulting discussion. The general lack of understanding in the responses indicates that the concept was new to those who replied.
A patent has been granted on Variable Size Block Ciphers.
In this Variable Size Block Cipher core we have two main component types:
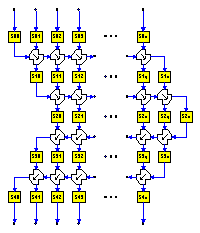
In the figure, each box represents a table, and each hourglass shape represents a BBM. Plaintext data bytes enter at the top, are substituted, mixed right, substituted, mixed right, substituted, mixed left, substituted, mixed left and substituted into ciphertext. Dynamic table selection is not shown.
The essence of the design is an inability to externally isolate or distinguish one table from another. This inability is directly related to the exact balance in the high-quality BBM mixing, as opposed to an exponential increase in complexity from repeated low-quality mixing with confusion.
Tables are widely used in many designs, and even keyed tables are not that unusual. But in this design all of the inter-element diffusion occurs in distinct, one-way diffusion layers composed of linear Balanced Block Mixing (BBM) operations, and this is new.
This separation between mixing
(diffusion)
and keyed substitution
(confusion)
is beneficial in that the two operations can be seen,
understood, and measured separately. In conventional designs,
confusion and diffusion are often combined, which makes these ciphers
difficult to understand or measure. And conventional ciphers
do not scale down to testable size.
A Variable Size Block Cipher is scalable in a way that few designs are:
This ability to scale a single design between large real ciphers
and small testable models almost cannot be overemphasized.
Cryptography
does have better-known structures and designs, but
cryptography simply does not have a proven methodology
which -- if only followed -- will guarantee a strong design. This
means that testing is exceedingly important, and real ciphers are
far too large for many types of test.
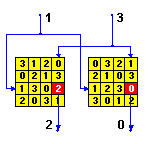
A Balanced Block Mixer can be considered an orthogonal pair of Latin squares. The two inputs select "row" and "column" and return the value from the selected element of each square. This "mixes" or combines the two input values into the two output values with some useful properties for this design:
Even a single bit change in one mixing input will produce some
change in both mixing outputs.
And if each output is
substituted through a keyed table, each table will produce a random
result value. So even a single bit change on one input will produce
a new random result on both outputs.
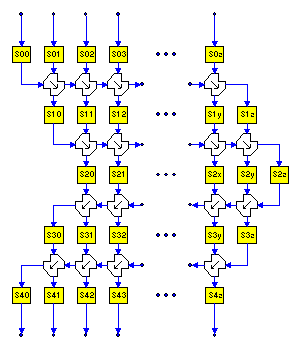
To have a block cipher which can be expanded arbitrarily, to the byte, at ciphering time, we are necessarily limited to operations which can be applied byte-by-byte. But we are not limited to performing the whole transformation on each byte separately as we would in a stream cipher. Instead, we can apply operations which, though byte-size, produce "carry" information as an input to the next byte operation. When we do this multiple times in both directions we can approach the desired block cipher goal of apparent overall diffusion.
In the figure, each plaintext byte enters the top of the
structure and is immediately confused through an invertible
substitution table.
The substituted value then mixes
into a
one way diffusion
path running across the unknown width of the
block. Each of the funny-looking hourglass shapes represents a separate
Balanced Block Mixing
(BBM), a two-input two-output mixing operation which proceeds in the
direction of the arrow.
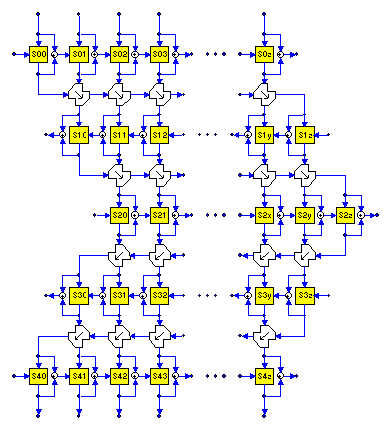
While each substitution in the figures has a particular number (e.g., S00 for the leftmost top substitution), these are just positions for tables and not particular tables themselves. Considerable strength is added by selecting the table for each next position based on an exclusive-OR of the data and substituted data values in the preceding position. This "dynamic table selection" virtually eliminates the possibility of having even two blocks ciphered under the same table arrangement.
Dynamic table selection also provides a zero-latency form of
"chaining" which can be used for authentication. (The initial
table values can be explicitly reset before each block if blocks
are to be ciphered independently.)
The intent of the design is to mix every input byte into every output byte in a way which appears to be a huge overall random substitution. Most of this mixing occurs in the four BBM one-way diffusion layers, and some occurs in the dynamic table selection of the confusion layers.
While one might think that two one-way diffusion channels would be sufficient (one each way, or both the same way with an end-around-carry), in practice, random inputs occasionally "cancel" earlier changes, so that -- occasionally -- no propagation occurs. This can be made rare by having a wide diffusion channel. And here we have not only two layers of Balanced Block Mixing in each direction, but also the dynamic table selection to carry diffusion across the block. In this particular design, there are 4 specific 8-bit one-way diffusion layers, plus 5 layers of dynamic table selection. With 64 substitution boxes, we thus have a 62-bit diffusion path between adjacent columns.
The first two right-going BBM layers assure that almost any left-side data change will be conducted across the block, and so complicate attempts to isolate the leftmost column. After the first left-going diffusion layer, we should have a complex function of every input byte across the entire block. The final left-going BBM layer is used to protect against random cancellation effects which might otherwise affect the left-going diffusion.
By conducting a
defined plaintext attack,
and running through all
values for the first few columns, it should be possible to detect
cancellations in both carry paths as a lack of ciphertext changes
to the right. These are all evenly distributed, however, and seem
to provide no information about particular values which could be
used in reconstructing the table contents. This issue is discussed in
Defined Plaintext Attack on a Simplified BBM VSBC
on these pages.
Since we use invertible substitution tables, we can "undo" any table translation by sending the resulting value through the corresponding inverse table. The form of Dynamic Table Selection used here takes both the input and output table values and exclusive-OR's them, which selects the same next table whether we have forward or inverse tables. So a right-going Dynamic Table Selection layer is reversed by a right-going Dynamic Table Selection layer using inverse tables.
The inverse of the simple linear BBM component used here is just another occurrence of that same BBM component. In the one-way diffusion layers used here, a left-going diffusion (L) is the inverse of a right-going diffusion (R), and vise versa. In the current design we have four one-way diffusion layers for enciphering, in the sequence <R R L L>. When deciphering, to reverse the bottom "L" layer, we need an "R", and so on. So the deciphering diffusion layer sequence is also <R R L L>.
This means that exactly the same ciphering routine can be used for both enciphering and deciphering. For deciphering we use inverse tables and take the initial values (IV's) in reverse layer order. Both of these conditions are easily handled during keying.
DES has a fixed block size and we have somehow managed thus far, so it may seem like overkill for a cipher to have multiple block sizes. But there is almost no cost for this, and it must be admitted that having blocks of various size -- or even dynamically variable size -- sometimes can provide a better fit to the overall system than any single fixed block size. But perhaps the biggest benefit comes from the ability to cipher in very large blocks.
If plaintext really does contain uniqueness at a rate of only about one bit per character, a legacy 64-bit block covers only about eight bits of uniqueness. This is the situation encountered in the classic codebook attack. This sort of attack is not avoided by having a larger keyspace, but can be avoided by using a wide, unbiased selection of plaintext blocks. Normally this is done by using a chained operating mode to randomize the plaintext. But increasing the block size to 64 bytes or more can collect enough uniqueness in the plaintext block so that randomization can be avoided.
By increasing the block size to 64 bytes or more we may be able to operate in "electronic code book" (ECB) mode instead of "cipher block chain" (CBC) mode. This means that we may not need to develop, send or store an initial value (IV), which would otherwise expand the ciphertext. And it also means that blocks can be both enciphered and deciphered independently, even if they are received out-of-sequence, as may happen in packet-switching transmission.
In conventional block cipher designs, the block size is so
small that we can scarcely consider displacing some data with
other information. But when we have a large block, there is
room for other information, at a relatively small overhead.
Typical applications include Dynamic Keying and Authentication.
Primary keying generally consists of shuffling each substitution table with a keyed cryptographic random number generator (RNG), twice. Primary keying can use fairly conventional technology, and is largely independent of the ciphering core itself. One example of a keying system is described in A Keyed Shuffling System on these pages.
Primary keying takes about 1 msec per table on a 100 MHz processor,
which is fast enough on a human scale. Primary keying does take time,
because it is specifically intended to perform as much computation
as possible -- once -- instead of having computation repeated with
every block at ciphering-time.
We assign an 8 bit strength to each table. Although an arbitrary table permutation contains 1684 bits of independence, we reason that if The Opponents can find (that is, absolutely identify and confirm) one value, they can probably find another. Since each table value is 8 bits, we assume a table strength of just 8 bits.
With this sort of five
confusion
layer
and four
one-way diffusion
layer structure, we believe that only three of the layers contribute
independent
strength.
Therefore, for a small 8-byte block, we expect to see
True zero-latency dynamic keying is available by placing keying values in each data block along with data. This will of course expand the ciphertext by the size of the keying field, but even a 64-bit dynamic keying field is only about 12.5 percent of a 64-byte block. This sort of keying can be used in any true (that is, avalanching or data diffusing) block cipher with room for extra data.
Strong block-by-block authentication is available similar to dynamic keying. Authentication values are placed into each data block along with data. Potentially, this can avoid a higher-level scan across the data with a cryptographic hash function. The exact same field can provide both authentication and dynamic keying.
Here we present various attacks and comment on their likelihood of success on this particular cipher. Recall that attacks are not algorithms, but instead just general approaches which must be reinvented for every new type of cipher.
Try each possible key until the message deciphers properly. Try most-likely keys first.
A keyspace of at least 120 bits should be sufficient to prevent exhaustive search in the foreseeable future. The keying system for the VSBC core has a keyspace substantially beyond this value, mainly because this produces a convenient design.
No cipher can do very much about key search attacks if there are only a relatively small number of possible keys, and if some keys are vastly more probable than others. It is the responsibility of the larger system to prevent this.
Try various keys on known plaintext and compare the resulting ciphertext to the actual ciphertext, to try and build the correct key value.
If a user has the ability to generate specific keys which are used by the VSBC core on data, it is quite likely that the external cipher system has already failed. However, even in this situation, key selection seems unlikely to help The Opponent. Sure, they can force particular table values by manipulating the key, but they can do that without going through the keying process. The Opponent's main problem in attacking the cipher is that the one-way diffusion layers appear to couple the various tables together so that a single table cannot be isolated and worked on separately.
The Opponent accumulates a mass of ciphertext material and tries to find relationships within the data.
This is a general class of various specialized attacks which all use only the exposed ciphertext as opposed to particular knowledge of the plaintext or access to the ciphering system itself.
Collect as many ciphertexts as possible and try to understand their contents through usage and relationships; then, when a ciphertext occurs, look it up. This treats the block cipher like a code, and is the classic approach to code-breaking.
Just as some letters are more frequently used than others, words and phrases also have usage frequencies, as do blocks which contain plaintext. If the cipher block size is small (under 64 bytes), and if the plaintext is not randomized, and if dynamic keying is not used, and if the ciphering key is not changed frequently, it may be possible to build a codebook of block values with their intended meanings.
Codebook attacks of any sort are ideally prevented by having a large number of block values, which implies a large block size. Once the block size is at least, say, 64 bytes, we expect the amount of uniqueness in each block to exceed anyone's ability to collect and form a codebook.
Since the complexity of any sort of a codebook attack is related to block size only, doing "triple" anything will not affect increase this complexity. In particular, this means that Triple DES is no stronger that DES itself under this sort of attack, which is based on block size and not transformation complexity.
Somehow "obtain" both the plaintext and the corresponding ciphertext for some large number of encipherings under one key.
First, since the VSBC core described here has an internal state typically 512 times as large as a 64-byte data block, we know that a single plaintext and ciphertext pair simply do not contain sufficient information to reveal the full internal state. Note that a single known plaintext and ciphertext pair probably would identify a DES key.
Larger amounts of known plaintext and ciphertext will of course surpass the required information, but the question is how The Opponent might use it. The problem is a supposed inability to distinguish one table from another and so work on one table at at time.
Collect as many ciphertexts and associated plaintext blocks as possible; then, when a ciphertext occurs, look it up.
Small block ciphers prevent codebook attacks by randomizing the plaintext (often with Cipher Block Chaining) so that the plaintext block values are distributed evenly across all possible block values. But not all block ciphers are always applied properly.
Codebook attacks are ideally prevented by having a large number of block values, which implies a block size. To prevent this attack for the future, we need a block size of at least 128 bits, and even then still require the plaintext to be randomized. If we wish to avoid randomizing with CBC, we need a block which is large enough so the uniqueness it does contain assures that there will be too many different blocks to catalog. A reasonable power-of-2 minimum size to avoid randomization would be at least 64 bytes.
Without knowing the key, arrange to cipher data at will and capture the associated ciphertext. Dynamically modify the data to reveal the key, or keyed values in the cipher.
The point here is not to decipher the associated ciphertext because The Opponent is producing the original plaintext. If The Opponents have chosen plaintext capabilities, they can probably also submit arbitrary ciphertext blocks for deciphering.
The weakness to be exploited here depends upon the ciphering system beyond the core cipher per se. If the primary keying values change with each message, and the ciphering keys are not under the control of the user (if the system uses message keys), there simply is no fixed internal state to be exposed.
If the primary key remains the same for all messages, then there will be some keyed state to try and ferret out. But if the ciphering system uses dynamic keying fields (with values again not under the control of the user), there can be no completely-known Chosen Plaintext blocks for use in analysis.
If the ciphering core is used raw, without primary re-keying and also without dynamic keying, the Dynamic Table Selection still uses whatever "uniqueness" exists in the data to change the tables used in the block transformation.
It is not clear that there exist any statistical relationships in the VSBC core which can be exploited better by Chosen Plaintext than by Known Plaintext.
Create as many ciphertexts and associated plaintext blocks as possible; then, when a ciphertext occurs, look it up.
This is much like the previous codebook attacks, now with the ability to fill the codebook at will and at electronic speeds. Again, the ability to do this depends upon the cipher having a relatively small block size and not having a dynamic keying field. How difficult such an attack would be depends upon the size of the block, but a VSBC may have no particular block size.
With a multi-layered structure, given known-or defined-plaintext, search the top keyspace to find every possible result, and search the bottom keyspace to find every possible value.
With a two-level construct and a small block size, matches can be verified with a few subsequent known-plaintext/ciphertext pairs. Of course, three and more-level constructs can always be partitioned into two sections so a meet-in-the-middle attack can always be applied; this just may be pretty complex.
The Mixing core avoids meet-in-the-middle attacks by using a three-level construction, in which each layer has a huge amount of keyed state or "keyspace."
Through extensive ciphering of fixed plaintext data under a variety of different keys, it may sometimes be possible to associate key bits with the statistical value of some ciphertext bits. This knowledge will break the cipher quickly.
This is a rather unlikely circumstance, albeit one with absolutely deadly results.
Exploit known properties of particular known substitution tables to effectively reduce the number of "rounds" in an iterated block cipher.
The original form of Differential Cryptanalysis mainly applies to iterated block ciphers with known tables, neither of which are present here. However, the general concept is like the expected VSBC attack.
The general idea of trying to relate byte values in adjacent columns is one of the major possible attacks on VSBC's. This is made difficult by using Balanced Block Mixing to conduct diffusion, and by having multiple diffusion layers. Each BBM guarantees that a change in a data value can "cancel" at most one of the mixed outputs, which leaves the other mixed output to carry the change across the block.
Another difficulty in applying Differential Cryptanalysis to
a VSBC would be in handling the Dynamic Table Selection feature.
Each different input value will actually select a different set of
tables, and, thus, a completely different transformation. It is
hard to attack a transformation which changes its structure
whenever it is probed.
Summary of Advantages
Strength
Flexibility
Also see:
Last updated: 1998-03-21